- Home
- News
- General News
- The Long Read: The...
The Long Read: The AI revolution
02-04-2024
Many ESRF scientists are turning to machine-learning algorithms, for insights that would be much too laborious – even impossible – to gain manually. Our Long Read articles take a deep dive into a topic of scientific importance: this month, how AI can boost synchrotron science. This article was first published in the March issue of the ESRFnews magazine.
For what was once a purely technical subject, machine learning has hardly been out of the news. Beginning in late 2022, the world has had to come to terms with the impact of a number of groundbreaking, generative artificial-intelligence (AI) models – notably the ChatGPT chatbot by the US company OpenAI, and text-to-image systems such as Midjourney, developed by the US company of the same name. Everyday conversations cannot avoid the debate over whether we are living amid a fantastic new industrial revolution – or the end of civilisation as we know it.
All this popular controversy can detract from a quieter – but no less important – machine-learning evolution taking place in the scientific realm. Arguably this began in the 1990s, with greater computing power and the development of so-called neural networks, which attempt to mimic the wiring of the brain, and which helped to popularise AI as an overarching term for machines that ape human thinking. The real acceleration, however, has taken place in the past decade or so, thanks to the storage and processing of “big data”, and experiments with layered neural networks – what has come to be called deep learning.
Of this revolution, synchrotron users – who are among the world’s largest producers of scientific data – stand to be great beneficiaries. Machine learning has the potential to streamline experiments, reduce data volumes, speed up data analysis and obtain results that would otherwise be beyond human insight. “We’ve been amazed in many ways by the results we could produce,” says Linus Pithan, a materials and data scientist based at the German synchrotron DESY, who ran an autonomous crystal-growth experiment at the ESRF’s ID10 beamline with colleagues last year. “The quality of the online data analysis was astonishing.”
Formerly a member of the ESRF’s Beamline Control Unit where he helped develop the new BLISS beamline control system, Pithan is well placed to test the potential of machine learning in synchrotron science. The flexibility of BLISS was necessary for him and his colleagues to integrate their own deep-learning algorithm, which they had trained beforehand to reconstruct scattering-length density (SLD) profiles from the X-ray reflectivity of molecular thin films. Unlike the forwards operation – calculating a reflectivity curve from an SLD profile – this inverse problem can be painfully tedious to solve even for an experienced analyst: the data are inherently ambiguous, because they do not include the phase of the scattered X-rays. Indeed, it is a demanding task for a machine too, which is why at the beamline Pithan’s group made use of an online service known as VISA to harness the ESRF’s central computer system.
The success of the automation was immediately apparent (Figure 1). From the reflectivity measurements, the deep-learning algorithm could output SLD profiles and thin-film properties such as layer thickness and surface roughness in real time, and thereby stop in-situ molecular beam deposition at any desired sample thickness between 80 Å and 640 Å, with an average accuracy of 2 Å [1]. “The machine-learning model was able to ‘predict’ results within milliseconds,” says Pithan. “In a way, we transferred the time that is traditionally needed for the manual fitting process to the point before the actual experiment where we trained the model. So by the time of the experiment, were able to get results instantaneously.”
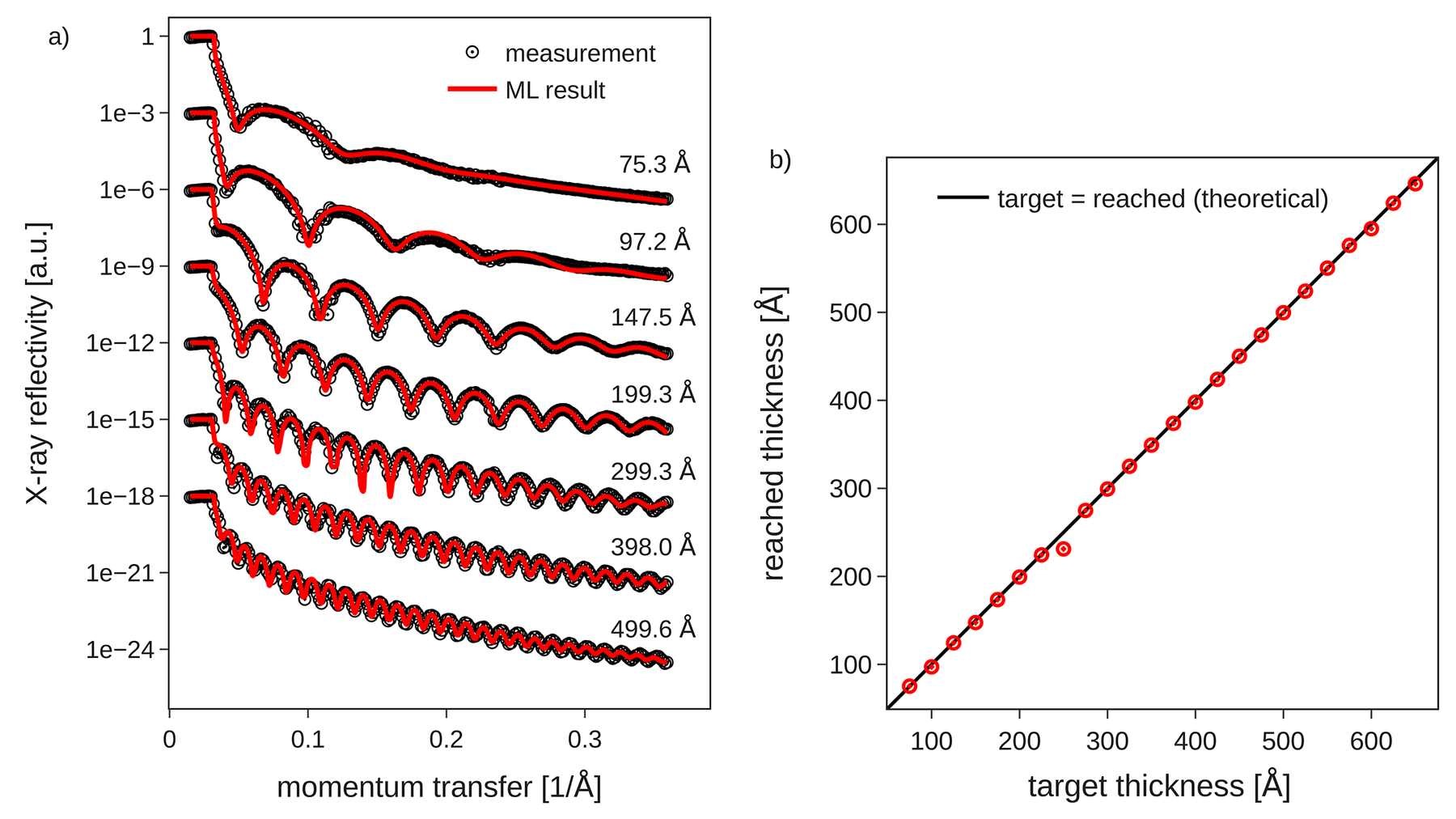
Fig. 1: Measure data compared with deep-learning predictions for a crystal-growth experiment at ID10 [1]. a) The algorithm predicts the relationship between X-ray momentum transfer and reflectivity oscillations, which are a measure of properties such as thickness and surface roughness. b) The algorithm predicts when to stop the in-situ molecular beam deposition for a certain desired film thickness.
Strategic development
The ESRF has been anticipating a rise in machine learning for many years. It forms part of the data strategy, and is one of the reasons for the ESRF’s engagement in various European projects that support the trend: PaNOSC, which is a cloud service to host publicly funded photon and neutron research data; DAPHNE, which aims to make photon and neutron data accord to “FAIR” (reusable) principles; and most recently OSCARS, which promotes European open science. Vincent Favre-Nicolin, the head of the ESRF algorithms and scientific data analysis group, is wary of claiming that machine learning is always a “magical” solution, and points out the toll it can take on computing resources. “But for some areas it makes a real difference,” he says.
Aside from experimental automation, one of these areas is image segmentation. In daily life humans find this easy – we have no problem working out where our fingertips end and the pages of a magazine begin, for instance – but it can be laborious in certain areas of synchrotron science, such as tomography. ESRF postdoc François Cadiou, who is involved in BIG-MAP (part of the European Commission’s BATTERY 2030+ large-scale research initiative for sustainable batteries), is developing machine-learning algorithms to quickly identify the different constituents of porous electrodes, such as the active material, the conductive polymer binder and the electrolyte. Accuracy is key here, as researchers need to know the exact conditions that promote superior battery performance over potentially catastrophic failure.
Cadiou and his colleagues are developing a type of interactive AI algorithm called active learning. They begin by annotating some images in a tomographic volume manually, to set up their model for training. When its learning slows, the model moves on to unannotated volumes, selecting those it has the most to learn from. The human researchers review its output, applying corrections to be integrated into the next training loop. This next loop is then concluded, and another, and so on. According to Cadiou, training a model to segment one volume with more classical deep-learning algorithms can take a week or two due to the manual image-annotation process, whereas this active learning procedure gives results of sufficient fidelity in about a day. “The speed-up is all the more required when we’re working with in-situ or operando data, as there are then numerous volumes to analyse conjointly,” he says.
Many other ESRF users are turning to machine learning to assist in segmentation, especially when the raw images contain the unprecedented levels of detail provided by the new Extremely Brilliant Source. Backed by a grant from the European Research Council, ESRF scientist Alexandra Pacureanu is turning to automated segmentation to resolve neural circuits in mammalian brains in data from the ID16A nano-imaging beamline. Meanwhile, drawing on hierarchical phase-contrast tomography (HiP-CT) data taken at the ESRF’s flagship BM18 beamline, researchers involved in the Human Organ Atlas (HOA) project (co-funded by the Chan Zuckerberg Initiative) are relying on automated segmentation to identify various anatomical structures inside organs – particularly blood vessels, but also airways in the lungs, the “glomeruli” or filtering units of the kidneys, and parts of the brain (Figure 2).
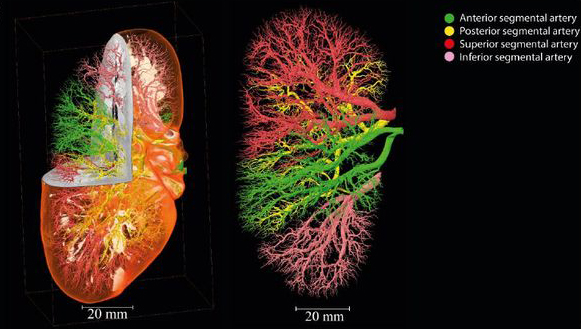
Fig. 2: Painstaking manual segmentation of ESRF tomographic data reveals the vasculature of a human kidney for the Human Organ Atlas project. It also provides valuable training data for deep-learning algorithms that will be able to do the same job much faster (bioRxiv, doi: 10.1101/2023.03.28.534566)
Training, training, training
HiP-CT data expose the challenge –and potential –for machine learning in segmentation. Given that it can deliver images of entire organs, with a resolution down to the single cell in regions of interest, the data volumes are massive, often a terabyte or more, requiring hefty processing power. In addition, features such as blood vessels are genuinely hierarchical – meaning that segmentation has to be performed over disparate length scales – and vary greatly from person to person. Perhaps the trickiest problem is the sheer novelty of the imaging technique: there are simply no data already available that a machine-learning algorithm can draw on to train itself. “This is something that is often glossed over, but machine learning can only be as good as the data used to train it,” says HOA scientist Claire Walsh at University College London in the UK. “And making these data is a huge undertaking. We have two experts labelling each dataset, and a third to go over the combined labels and mark areas that need improvement.”
The HOA has an open data policy. That permits another avenue for machine learning, for its datasets – which include entire organs, either healthy or afflicted by various diseases – can be mined by independent research groups, using their own algorithms and driven by their own research goals. Indeed, automated mining of open data is behind what is arguably the most scientifically influential deep-learning product of recent years: AlphaFold, which is developed by DeepMind, a research laboratory based in London, UK, and owned by the parent company of Google. Trained on experimental (largely synchrotron-derived) data in the Protein Data Bank, AlphaFold has succeeded where humans could not, by predicting – with incredible accuracy – protein structures from their amino acid sequences. AlphaFold predictions can in turn boost the experimental determination of new structures (Figure 3).
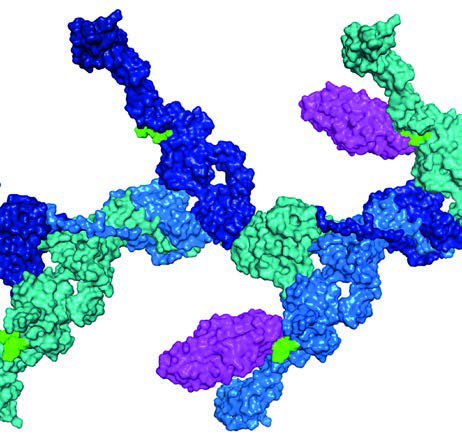
Fig. 3: In 2022, combined with experimental data from the ESRF and SciLifeLab in Stockholm, Sweden, the deep-learning tool AlphaFold enabled researchers to determine the structures of two human proteins, GP2 and UMOD (pictured). The proteins are known to counteract the bacteria behind gastrointestinal and urinary tract infections (Nat. Struct. Mol. Biol. 29, 190; doi: 10.1038/s41594-022-00729-3)
In other areas of synchrotron science, machine learning is not so much about breaking new ground, but making existing ground more accessible. Take X-ray spectroscopy, for instance. This can be an incredibly versatile technique, providing insights into the makeup of all kinds of samples – from historic paintings, to polluted soil, to new catalysts, and much else besides. But interpreting individual spectra can be as much an expert task as classifying fingerprints – and one that not all users will be up to. Machine learning can be trained to automatically extract information, such as atomic bond lengths, coordination numbers, charges and so on. “The goal is to democratise the analysis of X-ray spectra to non-expert users,” says ESRF software development engineer Marius Retegan, who hosted a microsymposium on the topic at this year’s User Meeting.
This type of automated tool for spectroscopy is still in its infancy, as experimental data are not yet consistently stored in standardised formats necessary for training. Still, spectroscopy users may already have resorted to machine learning without realising it. PyMCA – often regarded as the Swiss army knife for scanning spectroscopy data analysis – has supported users for more than 15 years, and relies on unsupervised machine learning.
The impact of machine learning will be greatest for the next generation of users. As part of the ENGAGE programme, the ESRF has three PhD students who are honing skills in computational physics. One of these is Matteo Masto, who is now in his second year developing deep-learning algorithms for coherent diffraction imaging, helping to retrieve lost phase information as well as those “empty pixels” that can be artefacts of even the best X-ray detectors. “More and more people, me included, now are trying to employ deep-learning methods for the phase problem, and it seems to show promising results,” he says. “Besides this, there is a lot more coming in the future for many other applications, such as de-noising, super-resolution and particle-defect identification and classification.”
The benefits of machine learning may not always be felt directly. Nicolas Leclercq, the ESRF head of accelerator control, believes a variant known as reinforcement learning – which learns on the fly from adjusting parameters, and therefore does not need well-labelled training data to begin with – could one day improve the optimisation of the ESRF storage ring. In the ESRF vacuum group, Emmanuel Burtin and Anthony Meunier have been using machine learning to identify sudden pressure rises, which are a proxy for various events in the storage ring – valves mistakenly opening or closing, air leaks, electron-beam perturbations, and so on. Classifying each of these events used to take a few minutes when it was done manually; now an algorithm can do it in less than a second. It can even expose new classes of event, and reclassify swathes of past events accordingly – all in all helping to make accelerator control more efficient [2].
Finally, of course, there is the freely available generative AI. Chatbots provide a quick – if not always reliable – means to research scientific topics, for example, or to help compose papers and other documents in foreign languages. More broadly, Favre-Nicolin anticipates a time when users have recourse to virtual beamline assistants to plug gaps in their experience, encouraging them to pursue more adventurous lines of enquiry. “They might ask, how can I do this experiment? Can you advise me on parameters?” he says. “It’s bound to happen relatively soon.”
Text by Jon Cartwright, editor of ESRFnews, March 2024 issue
References
[1] L. Pithan et al., J. Synchrotron Rad. 30 1064-1075 (2023); https://doi.org/10.1107/S160057752300749X
[2] A. Meunier & E. Burtin, ESRF Highlights 2023, p174 (2023).
partners



European Synchrotron Radiation Facility - 71, avenue des Martyrs, CS 40220, 38043 Grenoble Cedex 9, France.